In many Business Central implementations, there’s a recurring need: extract a distinct set of document identifiers from a filtered set of detail records. Whether you’re working with sales lines, purchase lines, ledger entries, or custom transactional data — the goal is the same: identify which documents are involved based on line-level criteria.
For years, a particular coding pattern has circulated as “best practice” in many organizations. It looks something like this:
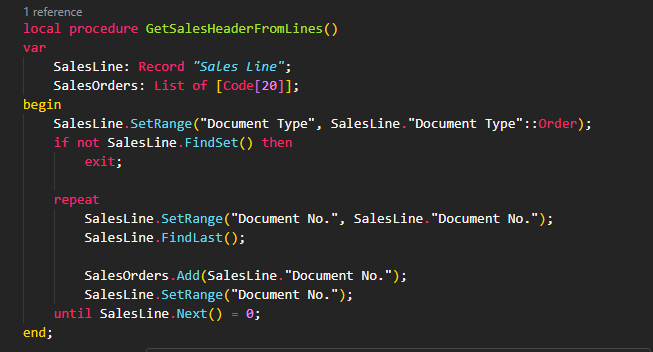
The idea behind this approach is to “skip” through the dataset, jumping to the last record of each group and collecting the document number. It feels efficient — fewer iterations, right?
But when tested against a simpler, more direct approach, the results tell a different story.
✅ The Simpler, Faster Alternative
Instead of skipping and resetting filters, just iterate through the filtered records and collect unique document numbers:
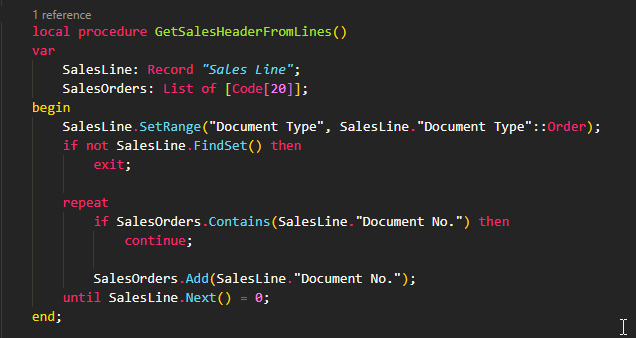
This method avoids repeated filtering and jumping. It simply walks through the dataset once and uses a list to track uniqueness.
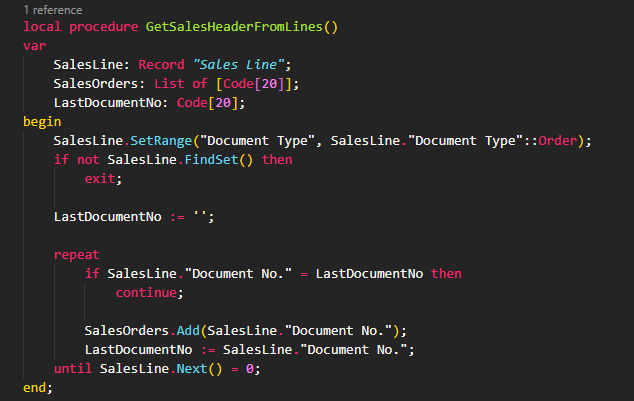
But we can be even more faster, if we know we set the correct key:
📊 Benchmark Results
Here’s a performance comparison based on 500 executions across different variants:
| Method | Execution Time | SQL Rows Read | SQL Statements |
| Group Skip (FindSet) | 1 min 6 sec | 1,369,141 | 214,501 |
| Group Skip (Find(‚-‚)) | 1 min 5 sec | 1,374,630 | 214,501 |
| Group Skip (FindFirst) | 57 sec | 1,369,141 | 214,500 |
| Simple Iteration with List | 7.7 sec | 249,500 | 500 |
| Iteration with Last Variable | 6.6 sec | 249,500 | 500 |
🔍 Why the Difference?
• The “group skip” method re-applies filters and performs additional reads per group.
• Each SetRange and FindLast triggers extra SQL operations.
• The simple iteration avoids all that — one pass, minimal reads, and deduplication handled in memory.
🧠 Conclusion
The myth of “skip logic” being faster doesn’t hold up under scrutiny. In fact, it’s significantly slower and heavier on SQL. If you’re extracting grouped identifiers from line-level records, favor a clean iteration with a uniqueness check.
Sometimes, the best optimization is the one that looks boring — and works brilliantly.
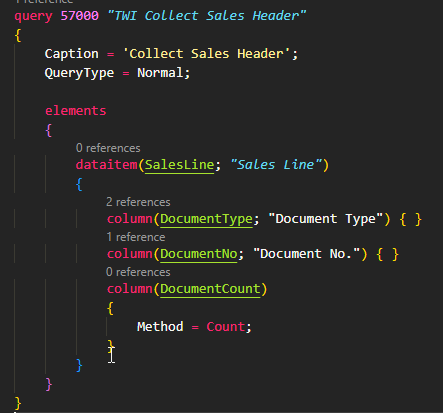
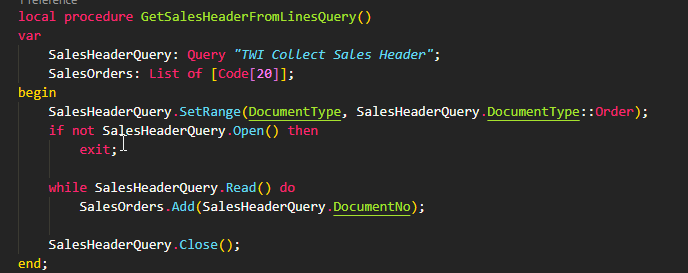
And of course, a perfect solution would be to use a Query instead (306ms).
Neueste Kommentare